| Question | How to handle/How it works? | References |
|---|---|---|
| What stores can be used as secondary stores | stores which implement the readOldest() method and currently only file and null stores | |
| Why does scribe create a new FileSystem for each file. | Based on our understanding of running/debugging this system for a while there are primary two reasons 1. hadoop filesystem object is cached as is singleton per JVM and since scribe is highly multi-threaded it would benefit from it. 2. DFSClient have a list of blacklisted nodes which AFAIK once formed are kinda static..so to avoid a complete outage that all datanodes are blacklisted and if a datanode was errenous on one connection a seperate thread connecting to the same datanode might be able to move forward. | http://hadoopblog.blogspot.in/2009/06/hdfs-scribe-integration.html |
| how to handle memory consumption going up | server->setResizeBufferEveryN(1); server->setIdleReadBufferLimit(32*1024); This patch is only available in 0.6 version of thrift. | https://groups.google.com/group/scribe-server/browse_thread/thread/09f57eaa034ab14a |
| Scenarios in which message loss can occur | (i) If a client can't connect to either the local or central scribe server the message will be loss. (ii) If a scribe server crashes it could lose a small amount of data that's in memory but not on disk goverend by max_write_size & max_write_interval (iii) Some multiple component failure cases, such as a resender can't connect to any central server and its local disk fills up | (iii) Some multiple component failure cases, such as a resender can't connect to any central server and its local disk fills up |
| When can duplication of messages occur | Some rare timeout conditions can lead to duplicate messages | http://highscalability.com/product-scribe-facebooks-scalable-logging-system |
| buffer store doesn't get drained unless you send a bogus message | JIRA - https://github.com/facebook/scribe/issues/35 | https://groups.google.com/group/scribe-server/browse_thread/thread/7205e3dd06a6601f |
| if you configure multiple bucket stores in a primary store config and a file store as secondary, then if one of the buckets in down in the store scribe moves to pushing data to secondary store instead of trying the other primary bucket's which are alive | 1. Patch not available in open source 2. Check whether we want this scenario | https://groups.google.com/group/scribe-server/browse_thread/thread/d650a0356d9e6de8 |
| Buffer store backs up data when primary store is down. When primary comes up buffer store sends too much of data thereby overwhelming the primary store | 1. Patch available to send dummy bogus message and achieve throttling. 2. Patch available in the inmobi | https://github.com/facebook/scribe/commit/0f32992c27a52fe19f26a521c9f82e1b579a9aa3 |
| Whether to retry sending messages | 1. based on must_succeed = YES/NO. Doen't play a role in case of Buffer Store | |
| How to figure out the sequence of files generated by scribe | 1. use timestamp 2. if (write_meta = YES) lastline will have scribe_meta: followed by next file name | |
| Can we reload the config | Only store specific configuration's can be reloaded. Scribe server related config's don't get dynamically reloaded without restarting scribe server. For config's refer - https://github.com/facebook/scribe/wiki/Scribe-Configuration |
| Issue | Resolution | Status |
|---|---|---|
| Scribe counters persistence. What if the scribe daemon goes down. How frequent are counters persisted. | OPEN | |
| Statergy to make data available to consumers at one place. | OPEN | |
| minute based file rotation can generate empty file | We are ok with this as we'll get data | CLOSED |
| UseCase | Behaviour/Observations | Monitoring to catch | Opens | How to try |
|---|---|---|---|---|
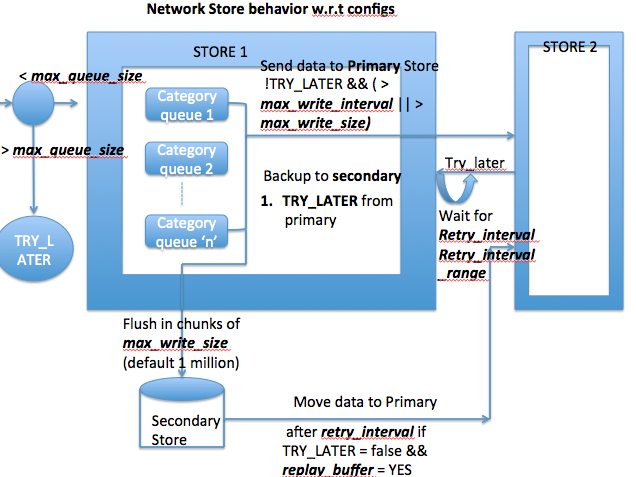
| 1. Buffer Store - Primary Store being File Store and secondary also being File Store | 1. primary is at /data/scribetestdata/ and secondary is at /tmp/scribetestdata and category name is "test" 2. primary store is not reachable( permission issue/disk is full) and client is sending new messages. 3. scribe server tries writing to primary fails and retries. 4. scribe server won't buffer to secondary till it reaches max_write_interval/max_write_size and keeps the message in memory and retries based on retry_interval/retry_range 5. In this example we fixed the permission issue in between the retry interval and scribe server wrote the message to /data/scribetestdata/test/test_00000 Exception < boost::filesystem::create_directory: Permission denied: "/tmp/scribetest/test" > in StdFile::createDirectory for path /tmp/scribetest/test " [Wed Nov 23 11:14:16 2011] "[test] Failed to create directory for file </tmp/scribetest/test/test_00000> | scribe server log monitoring for exception's | When does write to secondary store start. What config controls it? | |
| 2. Send large number of messages to multiple categories | Each category has it's own queue. Messages from multiple producers will get delivered in the order they went in the queue. No support for prioritization. | |||
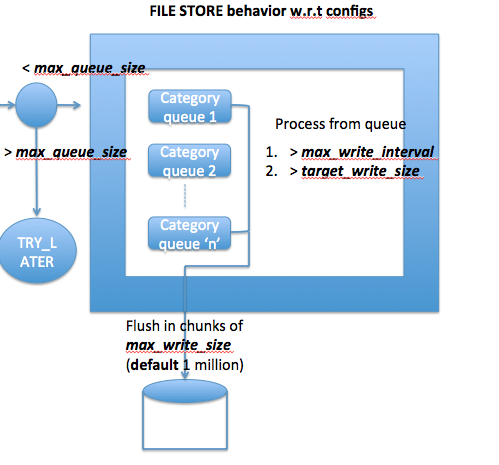
| 3. When are messages processed from queue - target_write_size or target_write_interval | whichever config among the two reaches first. Tested and it works. | |||
| 4. FIie rotation based on max size in primary and secondary stores | 1. Change max_write_size to a smaller value and send large number of messages. 2. File's get rotated based on max_write_size in both primary and secondary stores. | 3. Tested and works | |||
| 5. Primary to secondary failover | 1. Revoke permission's of primary store. 2. After target_write_size/target_write_interval whichever is reached, messages move to secondary store. 3. rotation in secondary store happens based on max_size configured/rotation_period which ever takes effect earlier. 4. scribe server keeps retrying based on retry_interval/retry_interval_range 5. fix the permission's of primary store 6. scribe server starts sending messages from secondary to primary and flushes the secondary. Parallelism of data transfer from primary to secondary is controlled via buffer_send_rate 7. Tested above and it works | |||
| 6. Generate Minute files | 1. file rotation within a category is controlled through max_size/rotate_period which ever happens first if both are set. 2. rotate_period=1m will generate minute files ( No data in 1 min generates 0 bytes files) | |||
| 7. Throttling through max_msg_sec/max_queue_size | 1. based on whichever reaches first scribe sever sends TRY_LATER to producer 2. Tested and works 3. This configuration cannot be reloaded dynamically as it's a scribe server config. | |||
| 8. Stats | 1. Scribe server gives stats and FILE Store also has stats Example Scribe Server stats inderbir@gs1102:~$ sudo ./scribe_ctrl counters 7463 test:retries: 83 test1:received good: 104002 scribe_overall:retries: 83 scribe_overall:received good: 239634 Example for file store stats File named scribe_stats generated inside the category directory eg: /tmp/scribe_tesdata/test/scribe_stats with contents 2011-11-24-12:46 wrote 11183 bytes in 0 events to file /tmp/scribetest/test/test_02223 |
| Dependency | Version |
|---|---|
| liboost | |
| thrift | |
| fb303 | |
| libevent | 1.4-2 |
| libhdfs |
sys.path.append('/usr/lib/python2.6/site\-packages/')
sys.path.append('path to thrift') # path where thrift python packages are
sys.path.append('path to fb303') # path where fb303 python packages are